


En 1982 aparecen los ordenadores personales, siendo hoy una herramienta común de trabajo. Esta difusión del ordenador ha impuesto la necesidad de compartir información, programas, recursos, acceder a otros sistemas informáticos dentro de la empresa y conectarse con bases de datos situadas físicamente en otros ordenadores, etc. En la actualidad, una adecuada interconexión entre los usuarios y procesos de una empresa u organización, puede constituir una clara ventaja competitiva. La reducción de costes de periféricos, o la facilidad para compartir y transmitir información son los puntos claves en que se apoya la creciente utilización de redes.
Los ordenadores suelen estar conectados entre sí por cables. Pero si la red abarca una región extensa, las conexiones pueden realizarse a través de líneas telefónicas, microondas, líneas de fibra óptica e incluso satélites.
Cada dispositivo activo conectado a la red se denomina nodo. Un dispositivo activo es aquel que interviene en la comunicación de forma autónoma, sin estar controlado por otro dispositivo. Por ejemplo, determinadas impresoras son autónomas y pueden dar servicio en una red sin conectarse a un ordenador que las maneje; estas impresoras son nodos de la red.
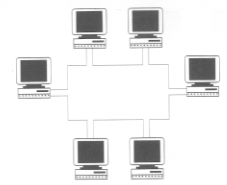
Dependiendo del territorio que abarca una red se clasifican en:
3. Características de una red
local
Los ordenadores conectados a una red local pueden ser grandes ordenadores
u ordenadores personales, con sus distintos tipos de periféricos.
Aunque hay muchos tipos de redes locales entre ellas hay unas características
comunes:
-Un servidor es un ordenador que permite a otros ordenadores que accedan a los recursos de que dispone. Estos servidores pueden ser:
De forma general, en una red, al nodo que pide un servicio o inicia una comunicación, se le denomina cliente. Al nodo que responde a la petición se le denomina servidor.
Cualquier medio físico o no, que pueda transportar información en forma de señales electromagnéticas se puede utilizar en redes locales como medio de transmisión.
Las líneas de transmisión son la espina dorsal de la red, por ellas se transmite la información entre los distintos nodos. Para efectuar la transmisión de la información se utilizan varias técnicas, pero las más comunes son: la banda base y la banda ancha.
Los diferentes tipos de red: EtherNet, TokenRing, FDDI, etc. pueden utilizar distintos tipos de cable y protocolos de comunicación.

Existen distintos tipos de cable coaxial, según las redes o las necesidades de mayor protección o distancia. Este tipo de cable sólo lo utilizan las redes EtherNet.
Existen dos tipos de cable coaxial:
Ventajas del cable coaxial:
![]()
Par trenzado
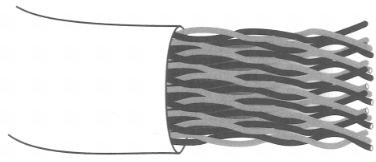
Cable de par trenzado
Los cables trenzados o bifilares constituyen el sistema de cableado usado en todo el mundo para telefonía. Es una tecnología bien conocida. El cable es bastante barato y fácil de instalar y las conexiones son fiables. Sus ventajas mayores son por tanto su disponibilidad y bajo coste.
En cuanto a las desventajas están la gran atenuación de la señal a medida que aumenta la distancia y que son muy susceptibles a interferencias eléctricas. Por este motivo en lugar de usar cable bifilar paralelo se utiliza trenzado y para evitar las interferencias, el conjunto de pares se apantalla con un conductor que hace de malla. Esto eleva el coste del cable en sí, pero su instalación y conexionado continua siendo más barato que en el caso de cables coaxiales. Tanto la red EtherNet como la TokenRing pueden usar este tipo de cable.
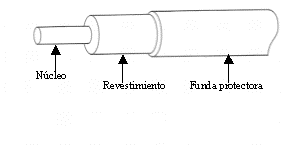
Por su naturaleza, este tipo de señal y cableado es inmune a las interferencias electromagnéticas y por su gran ancho de banda (velocidad de transferencia), permite transmitir grandes volúmenes de información a alta velocidad.
Estas ventajas hacen de la fibra óptica la elección idónea para redes de alta velocidad a grandes distancias, con flujos de datos considerables, así como en instalaciones en que la seguridad de la información sea un factor relevante.
Como inconveniente está, que es el soporte físico más caro. De nuevo, no debido al coste del cable en sí, sino por el precio de los conectores, el equipo requerido para enviar y detectar las ondas luminosas y la necesidad de disponer de técnicos cualificados para realizar la instalación y mantenimiento del sistema de cableado.
Ancho de banda: es la diferencia entre la frecuencia más alta y más baja de una determinada onda. El término ancho de banda hace referencia a la capacidad del medio de transmisión, cuanto mayor es el ancho de banda, más rápida es la transferencia de datos.
Por encima del ancho de banda las señales crean una perturbación en el medio que interfiere con las señales sucesivas. En función de la capacidad del medio, se habla de transmisión en banda base o transmisión en banda ancha.
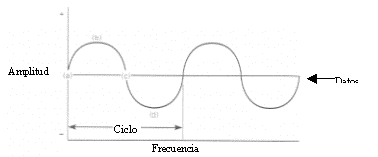
Banda base
Las redes en banda base generalmente trabajan con mayor velocidad de transmisión que las redes de banda ancha, aunque la capacidad de estas últimas de transmitir por varios canales simultáneamente pueden hacer que el flujo total de datos sea prácticamente el mismo en ambos sistemas.
La transmisión de banda base utiliza señales digitales sobre una frecuencia. Utiliza toda la capacidad del canal de comunicaciones para transmitir una única señal de datos.

Las ventajas de las redes en bus lineal son su sencillez y economía. El cableado pasa de una estación a otra. Un inconveniente del bus lineal es que si el cable falla en cualquier punto, toda la red deja de funcionar. Aunque existen diversos procedimientos de diagnóstico para detectar y solventar tales problemas, en grandes redes puede ser sumamente difícil localizar estas averías.
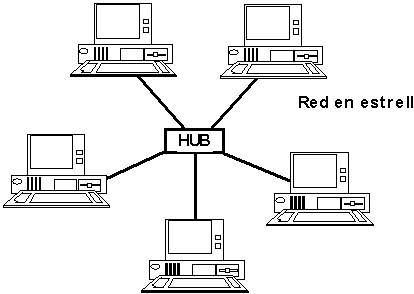
La detección de problemas de cableado en este sistema es muy simple al tener cada estación de trabajo su propio cable. Por la misma razón, la resistencia a fallos es muy alta ya que un problema en un cable afectará sólo a este usuario.
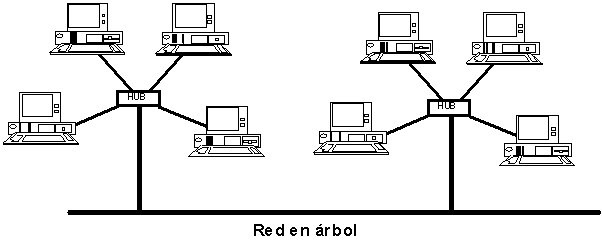
Estos suelen soportar entre cuatro y doce estaciones de trabajo. Los hubs se conectan a una red en bus, formando así un árbol o pirámide de hubs y dispositivos. Esta topología reúne muchas de las ventajas de los sistemas en bus y en estrella.
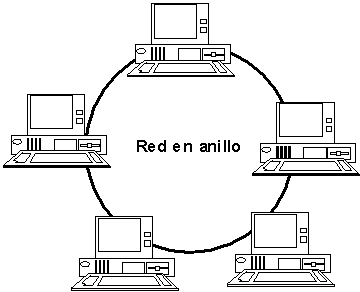
En una red local en anillo simple, un corte del cable afecta a todas las estaciones, por lo que se han desarrollado sistemas en anillo doble o combinando topologías de anillo y estrella.
La red EtherNet cuando utiliza cable coaxial sigue una topología en bus lineal tanto físico como lógico. En cambio al instalar cable bifilar, la topología lógica sigue siendo en bus pero la topología física es en estrella o en estrella distribuida.
Básicamente, el método de acceso por contención
permite que cualquier usuario empiece a transmitir en cualquier momento
siempre que el camino o medio físico no esté ocupado. En
el método determinístico, cada estación tiene asegurada
su oportunidad de transmitir siguiendo un criterio rotatorio.
7.1. Acceso por contención,
aleatorio o no determinístico
El método de contención más común es el CSMA(Carrier Sense Multiple Access) o en castellano Acceso Multiple Sensible a la Portadora. Opera bajo el principio de escuchar antes de hablar, de manera similar a la radio de los taxis. El método CSMA está diseñado para redes que comparten el medio de transmisión. Cuando una estación quiere enviar datos, primero escucha el canal para ver si alguien está transmitiendo. Si la línea esta desocupada, la estación transmite. Si está ocupada, espera hasta que esté libre.
Cuando dos estaciones transmiten al mismo tiempo habrá, lógicamente, una colisión. Para solucionar este problema existen dos técnicas diferentes, que son dos tipos de protocolos CSMA: uno es llamado CA - Collision Avoidance, en castellano Prevención de Colisión y el otro CD - Collision Detection, Detección de Colisión. La diferencia entre estos dos enfoques se reduce al envío o no de una señal de agradecimiento por parte del nodo receptor:
Collision Avoidance (CA): es un proceso en tres fases en las que el emisor:
-1º escucha para ver si la red está libre
-2º transmite el dato
-3º espera un reconocimiento por parte del receptor
Este método asegura así que el mensaje se recibe correctamente. Sin embargo, debido a las dos transmisiones, la del mensaje original y la del reconocimiento del receptor, pierde un poco de eficiencia. La red EherNet utiliza este método.
Collision Detection(CD): Es más sencillo, recuerda al modo de hablar humano. Después de transmitir, el emisor escucha si se produce una colisión. Si no oye nada asume que el mensaje fue recibido. Aunque al no haber reconocimiento, no hay garantía de que el mensaje se haya recibido correctamente. Cuando varias personas mantienen una conversación, puede haber momentos en los que hablen a la vez dos o más personas. La que intenta comunicar, al detectar que su conversación ha colisionado con otra, debe iniciar de nuevo la conversación. La red AppleTalk (Local Talk ) de Apple utiliza este método.
Si dos estaciones inician la transmisión simultáneamente se produce una colisión de las señales. La estación emisora, cuando detecta la colisión, bloquea la red para asegurar que todas las estaciones involucradas procesan el envío como erróneo. Entonces, cada estación espera un periodo corto de tiempo fijado aleatoriamente, antes de intentar transmitir de nuevo.
Aunque estos métodos puedan parecer imprecisos son de hecho muy exactos. Bajo condiciones de carga normales, raras veces ocurren colisiones y cuando aparecen, el emisor lo reintentará hasta que envíe su mensaje.
El método determinístico más usado es- el Token Passing o paso de testigo. En una red Token Passing una secuencia especial de bits, el testigo, recorre la red de una estación a otra siguiendo un orden predeterminado. Cuando una estación quiere transmitir, espera que le llegue el testigo y lo guarda; envía su mensaje que circula por toda la red hasta volver a la estación emisora, entonces libera el testigo que viaja hasta la siguiente estación de red.
Los sistemas Token Passing están diseñados para resistir fuertes cargas de trabajo. Al ser un sistema ordenado, una red local usando el método Token Passing puede aprovechar el ancho de banda de trabajo hasta en un 90%. En principio, en un sistema con mucho tráfico, los retardos son menores usando métodos de acceso determinístico (Token Passing) que por contención (CSMA/CA-CD). Sin embargo, en un sistema sin mucha carga el método de contención es bastante más rápido y eficaz.
Uno de los factores más importantes que se deben tener en cuenta para evaluar el comportamiento de una red es el número de estaciones. En las redes con acceso determinístico el token (testigo) circula a través de la red, teniendo cada estación derecho a transmitir antes de que se inicie una segunda vuelta. En una red de acceso por contención (aleatorio) el factor crítico será la carga de la red. La degradación del rendimiento es más predecible en una red Token Passing que en una CSMA/CD.
Algunos ejemplos de redes de acceso determinístico son la TokenRing de IBM y la Arcnet de Datapoint.
Cada red tiene perfectamente definido el sistema físico de transporte de información. El bloque de información básico que circula por la red se denomina datagrama, y tiene una estructura y tamaño característico para cada red:
Cabecera o header: tiene un tamaño definido y contiene la dirección de origen, la dirección de destino, el tamaño real de la información que transporta y tipo de servicio (protocolo o layer) que atiende. También contiene los datos temporales.
Segmento de datos o body: tiene un tamaño definido, aunque no necesariamente ocupado. Normalmente la información que se quiere enviar debe dividirse siendo necesario emplear varios datagramas.
Algunas redes emplean más de un tipo de datagramas. Así por ejemplo, las redes con método de acceso determinístico emplean datagramas distintos para el token y para la información.
Se entiende por protocolo el conjunto de normas o reglas necesarios para poder establecer la comunicación entre los ordenadores o nodos de una red. Un protocolo puede descomponerse en niveles lógicos o capas denominados layers.
El comité 802 del IEEE (Institute of Electrical and Electronic Engineers) desarrolla protocolos estándares divididos en capas que se corresponden con el modelo de 7 niveles de la ISO (International Standards Organization).
Para ilustrar la necesidad de un protocolo puede pensarse en el siguiente ejemplo, tomado de un campo totalmente distinto al de las redes de ordenadores, pero con problemas afines de transporte:
Suponga que se quiere trasladar los restos de un arco románico desde un monte hasta otro país. Con este fin se numeran las piezas, se desmonta en orden, según unas normas; las piezas se agrupan en contenedores numerados. Se realiza un primer transporte hasta un puerto de mar en contenedores (containers). En el puerto, los containers se agrupan y otra empresa de transportes los envía por vía marítima al país de destino. Puede suceder que los containers se envíen en distintos barcos, con escalas distintas En el puerto de destino la compañía naviera reagrupará los containers y los traspasará a la empresa de transporte terrestre, que los entregará al arquitecto en el lugar de emplazamiento. Allí en un orden inverso al empleado en origen se desagruparán las piezas y se montará el arco.
Al estudiar este ejemplo, se encuentra un paralelismo con otro ejemplo como puede ser el envío de una información entre usuarios de ordenadores en un hospital:
Suponga por ejemplo que quiere enviar una imagen de rayos-X, o el texto correspondiente a un historial clínico, de un departamento de un hospital a otro departamento.
Los datos que componen la imagen o el historial deben dividirse puesto que por su tamaño no puede emplearse un único datagrama. Además, esta información debe circular por una red con distintos soportes físicos y velocidades (coaxial, fibra óptica, etc.) y luego, por fin, recomponerla en el otro ordenador. Estos procesos plantean las siguientes cuestiones:
1. ¿Qué criterio se sigue para numerar las piezas originales?
2. ¿Con qué criterio se agrupan en las unidades de transporte (containers)?
3. ¿Cómo se ha decidido el tamaño de esas unidades de transporte en cada uno de los medios físicos?
4. ¿Qué criterio se emplea para reagrupar la información al llegar a un nuevo puerto (tipo de red)?; hay que tener en cuenta que los envíos pueden ir por distintos caminos, y llegar primero, los que salieron más tarde
5. ¿Qué criterio se sigue para desagrupar la información?
Los protocolos establecen todas las reglas correspondientes al transporte en sus distintos niveles. Cada nivel de abstracción corresponde a un layer.
En un nivel se trabaja con la aplicación que maneja la información que se desea transportar; en otro se carga la información en los datagramas; otro nivel controla el acceso al medio En el ordenador que recibe la información, los layers trabajan de forma análoga al que envía, pero en sentido inverso: controla el acceso al medio, lee los datagramas, reagrupa la información, y pasa los datos a la aplicación.
¿Qué hay que hacer para conectar dos redes distintas? El hecho de que sean redes distintas quiere decir que tienen distinto medio de transmisión, distinta estructura de la información que transmiten, distintas velocidades. Además, como puede intuirse con los ejemplos de transporte mencionados al hablar de protocolos, puede haber problemas de encaminamiento cuando la información pasa de una red a otra: dependiendo del tráfico, los paquetes de información pueden enviarse por caminos alternativos.
Un Router o Gateway es un dispositivo conectado en la red que une redes distintas. Por tanto, sus funciones son:
Adaptar la estructura de información de una red a la otra (datagramas con tamaños y estructuras distintas)
Pasar información de un soporte físico a otro (distintas velocidades y soportes físicos)
Encaminar información por la ruta óptima
Reagrupar la información que viene por rutas distintas
Un bridge une dos segmentos lógicos distintos de una misma red física. Dicho de otro modo: divide una red en dos subredes lógicas. El empleo de un bridge aísla el tráfico de información innecesaria entre segmentos, de forma que reduce las colisiones.
Un repeater amplifica la señal. Permite usar longitudes mayores de cable.
Para que dos ordenadores conectados a Internet puedan comunicarse entre sí es necesario que exista un lenguaje en común entre los dos ordenadores. Este lenguaje en común o protocolo es un conjunto de convenciones que determinan cómo se realiza el intercambio de datos entre dos ordenadores o programas.
Los protocolos usados por todas las redes que forman parte de Internet se llaman abreviadamente TCP/IP y son:
Se conoce como anfitrión o host a cualquier ordenador conectado a la red, que disponga de un número IP que presta algún servicio a otro ordenador.
Ordenador local (local host o local computer): es el ordenador en el que el usuario comienza su sesión de trabajo y el que se utiliza para entrar en la red. Es el punto de partida desde el cual se establecen las conexiones con otros ordenadores
Ordenadores remotos (remote host): aquellos con los que el usuario establece contacto a través de Internet y pueden estar situados físicamente en cualquier parte del mundo.
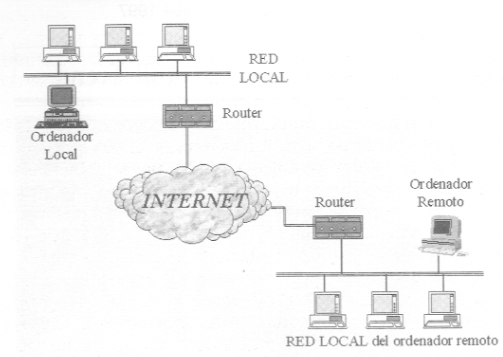
Cuando se utiliza un servicio en Internet como visualizar un documento de hipertexto se establece un proceso en el cual entran en juego dos partes:
Cada ordenador conectado a Internet tiene una dirección exclusiva y que lo distingue de cualquier otro ordenador del mundo, llamada dirección IP o número IP.
Dos ordenadores no pueden tener el mismo número IP, pero un ordenador sí puede tener varios números IP(dot quad notation).
Las direcciones IP están formadas por cuatro números separados por puntos, cada uno de los cuales puede tomar valores entre 0 y 255. Por ejemplo:
125.64.250.6
Cada vez que se ejecuta una aplicación para utilizar un servicio en Internet, el software de comunicaciones del ordenador local necesita conocer la dirección IP del ordenador remoto con el que se quiere entrar en contacto.
Como memorizar números resulta complicado existe un sistema de identificación por nombres.
Los encaminadores o routers permiten interconectar las distintas redes y encaminar la información por el camino adecuado.
El esqueleto de Internet está formado por un gran número de routers y la información va pasando de uno a otro hasta llegar a su destino.
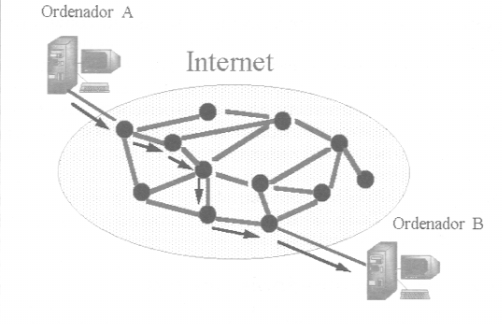
Existen muchos caminos posibles para llegar desde A hasta B. Cuando un router recibe un paquete decide cuál es el camino adecuado a seguir y lo envía al siguiente router. Éste vuelve a decidir y lo envía. El proceso se repite hasta que el paquete llega al destino final.
Cuando se transfiere información de un ordenador a otro ésta no se transmite de una sola vez, sino que se divide en pequeños paquetes. Así las líneas de transmisión, los routers y los servidores no se monopolizan por un solo usuario durante demasiado tiempo.
Generalmente por los cables de la red viajan paquetes de información provenientes de diferentes ordenadores y con destinos diferentes. Esta forma de transmitir información se denomina "conmutación de paquetes". Cada paquete de datos contiene:
-una porción de la información real que se quiere transmitir
-otros datos necesarios para el control de la transmisión
-las direcciones IP de los ordenadores de destino y de partida
Todas las operaciones relacionadas con el encaminamiento de los paquetes de información y la inclusión de etiquetas con las direcciones IP de origen y destino están determinadas por el protocolo IP.
Para que los ordenadores puedan hablar entre sí es necesario el protocolo de control de transmisión (TCP). Este protocolo:
-divide la información en paquetes del tamaño adecuado
-numera esos paquetes para que puedan volver a unirse en el orden correcto
-añade cierta información extra, necesaria para la transmisión y posterior descodificación del paquete. También para detectar posibles errores en la transmisión.
El software de TCP en el ordenador remoto se encarga de extraer la información de los paquetes recibidos, estos no tienen por qué llegar en el orden en el que fueron enviados, TCP se encarga de ensamblarlos en el orden correcto.
13.1. El nombre de los ordenadores en Internet
El sistema de nombres por dominio (Domain Name System, DNS) es un método para asignar nombres a los ordenadores a través de una estructura jerárquica.
Los nombres están formados por palabras separadas por puntos. Cada palabra representa un subdominio (FQDN: Full Qualified Domain Server) que a su vez está comprendido en un subdominio de alcance mayor:
web5.cti.unav.es
La primera palabra que aparece a la izquierda, por ejemplo: web5, es el nombre del ordenador, su nombre lo distingue de otros ordenadores que están dentro del mismo subdominio.
Cada una de las palabras que siguen corresponden a subdominios cada vez más amplios y que contienen a los anteriores. La última palabra, a la derecha, es el dominio principal o de primer nivel o de nivel superior.
Igual que las direcciones IP, los nombres por dominio de los ordenadores son exclusivos, no puede haber dos ordenadores distintos que tengan el mismo nombre. Sí es posible que un ordenador tenga más de un nombre que corresponda a un único número IP.
13.2. Los dominios de primer nivel
Los nombres de los subdominios son generalmente arbitrarios porque dependen de los administradores de las redes locales. Sin embargo los dominios de nivel superior y algunos subdominios amplios tienen reglas establecidas.
Existen diversos dominios de primer nivel convencionales:
-Nacionales: constan de dos letras que denotan a qué país pertenece el ordenador. España: es, Francia: fr, Gran Bretaña: uk...
-Internacionales y genéricos:
Internacionales: están reservados para las organizaciones de carácter internacional. Por el momento sólo existe uno: int.
Genéricos: pueden ser utilizados por entidades cuya actividad se extiende a uno o varios países. Comercial: com, organizaciones no comerciales: org, recursos de red: net.
Estados Unidos es una excepción ya que no se usa la terminación us como dominio principal. El motivo es que Internet tuvo su origen en las redes nacionales de Estados Unidos, por eso se utilizan dominios de primer nivel especiales:
edu: educación
mil: militar
gov: gobierno (no militar)
Para traducir los nombres por dominio a sus correspondientes números IP existen los servidores de nombres por dominio (DNS servers).
Debido a la gran cantidad de ordenadores que hay en la red y a los cambios constantes de estos es imposible mantener una base de datos centralizada que contenga todos los nombres por dominio existente. Sí existe una base de datos distribuida. Cada dominio principal, muchos subdominios y redes locales disponen de un servidor DNS con los datos de ordenadores que le pertenecen: sus nombres y sus números IP para poder traducir.
Cuando un ordenador local necesita conocer el número IP de un ordenador remoto se inicia un proceso:
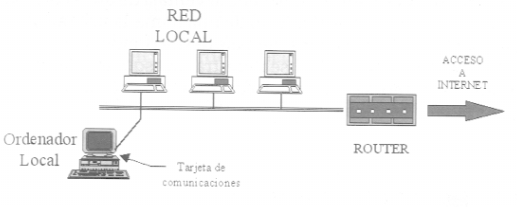
Existen dos formas de disponer de una conexión completa a Internet:
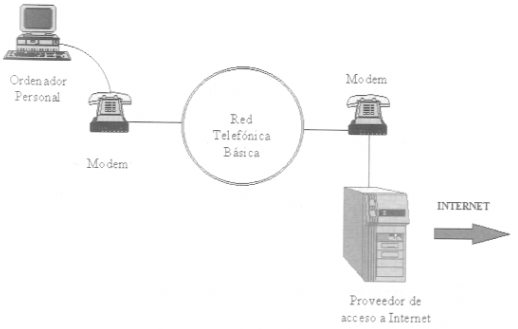
Se necesita un ordenador conectado a la línea telefónica a través de un modem. Se debe abonar el coste de la llamada telefónica durante el tiempo de conexión a red, además de la tarifa del proveedor del acceso.
Existe otra alternativa para el acceso telefónico a Internet, a través de InfoVía o un servicio similar. La ventaja es que el coste de la comunicación es el de una llamada urbana independientemente de la zona del país desde donde se efectúe la conexión.
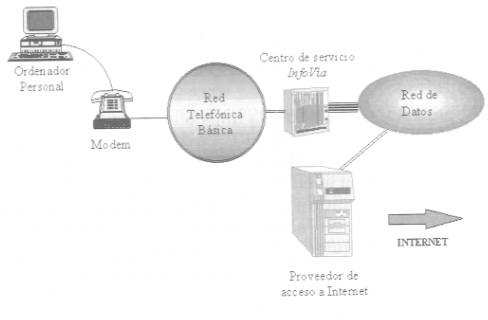
Para acceder a la red a través de una línea telefónica existen dos protocolos de comunicación. Estos protocolos hacen posible que el ordenador se convierta en un host con su número IP propio. Los protocolos son el SLIP (Serial Line Internet Protocol) y el PPP (Point to Point Protocol).
15. Breve historia de Internet
Sin embargo, hasta alrededor del año 1993, el uso de Internet estaba, en su mayor parte, limitado a círculos técnicos, científicos y académicos. La gran mayoría de la población, incluidas personas familiarizadas con la informática y el uso de ordenadores, nunca habían oído hablar de Internet. En determinado momento se produce un punto de inflexión en el cual todos los medios de difusión comienzan a hablar de Internet, el gran público empieza a interesarse por el tema, la Red comienza a insertarse en los distintos ámbitos de la sociedad y a tener implicaciones económicas importantes. Surge World Wide Web, la telaraña mundial.
El auge de Internet se debe en gran medida a la aparición de World Wide Web (WWW, W3 o simplemente Web), pero hay otros factores tecnológicos que contribuyeron a este fenómeno. El desarrollo de ordenadores cada vez más veloces, con más capacidad y a bajos precios, junto con el perfeccionamiento del software correspondiente, unido al avance de las telecomunicaciones, hace posible que en los países desarrollados se generalice el uso doméstico de Internet.
La creación de W3 y su continuo desarrollo y los avances tecnológicas que la hacen posible, son dos hechos intrínsecamente relacionados, en el que cada uno tira del otro.
World Wide Web fue desarrollada inicialmente en el CERN (Laboratorio Europeo de Física de Partículas) en Ginebra. Los trabajos iniciales comenzaron en 1989 y entre finales de 1990 y comienzos de 1991 aparecen el primer servidor Web y un browser (navegador) para interfaces de tipo texto. El objetivo perseguido entonces era que los físicos europeos en el ámbito de altas energías, cuyos grupos de trabajo estaban dispersos por varios países, pudiesen intercambiar conocimientos y datos de modo eficiente.
El sistema se extendió rápidamente por todo el mundo abarcando a las instituciones más diversas y permitiendo el acceso a todo tipo de información.
Quizás uno de los principales factores que contribuyó a la rápida aceptación y al crecimiento de W3 fue la aparición, en septiembre de 1993 del primer navegador gráfico. Éste permitía visualizar documentos que combinaban texto e imágenes en un formato muy atractivo.
Además del WWW, Internet ofrece otros servicios más antiguos como el correo electrónico, grupos de noticias, FTP, Telnet y Wais.
World Wide Web tiene algunas características que han facilitado su difusión:
Los documentos de hipertexto están constituidos por una combinación de texto y una serie de elementos multimedia; vídeo, sonido, representaciones de objetos en 3D y realidad virtual.
Lo que convierte a las páginas Web en hipertexto no son sus objetos multimedia sino los hiperenlaces. Estos se pueden ser palabras resaltadas, imágenes o iconos. Los enlaces son referencias a otros documentos en Internet. Al hacer clic en uno de ellos se accede a otra página Web, o se activa un elemento multimedia, o se accede a otros servicios de Internet (FTP, inicio de una sesión Telnet o el envío de un correo electrónico, etc.)
El enlace es una vía de acceso a otro recurso de Internet, que puede estar en el ordenador local o en otro ordenador en cualquier parte del mundo. Con el hipertexto el usuario no debe preocuparse de direcciones, protocolos o tipos de recursos; todo lo que debe hacer es clic con el ratón sobre el hiperenlace correspondiente.
Los hiperenlaces son los que dan a WWW la imagen de una gran telaraña que envuelve a todo el mundo. Ellos originan que los servidores de todo el planeta estén, desde el punto de vista del usuario, entrelazados por un entramado de referencias. Haciendo clic sobre los enlaces se va saltando de un documento a otro, de país en país, explorando recursos inimaginables. En eso consiste la navegación por Internet a través de WWW.
También las universidades, los fabricantes de navegadores y los proveedores de servicio tienen en sus páginas iniciales orientaciones para comenzar a navegar por Internet.
Un buscador es, una página que contiene un enorme catálogo, más o menos, ordenado por temas, para localizar lo deseado y no perderse en la abundancia de páginas de la red.
También se puede buscar información concreta escribiendo una o varias palabras que describan lo que interesa y el buscador facilita una relación de las páginas donde se puede encontrar, junto con una breve descripción de la misma.
Se pueden encontrar varios buscadores, en la página "Búsqueda de información" que facilita la página principal del servidor de la Universidad de Navarra:
Los buscadores más conocidos son: Yahoo, Altavista, Infoseek, Lycos, Excite, Webcrawler, etc.
Las conexiones a la red desde la Universidad suponen alrededor de un millón y medio de consultas al día, por lo tanto es importante el equilibrio de la carga de la red por los distintos servidores proxy.
Los proxies instalados en una red también tienen una función "caché". Cuando se solicita una conexión a la red (URL), la página que se ha "bajado" hasta el ordenador a través del navegador, se guarda en la memoria de ese servidor proxy durante un periodo de tiempo y así, cuando se vuelve a solicitar esa dirección desde otro ordenador de la red, el servidor proxy le ofrece la página que tiene guardada en la memoria, consiguiendo una mayor velocidad de respuesta y un ahorro en el tráfico de la red.
16.3.1. Configuración de los proxies en la red de la Universidad
Dentro del programa navegador hay que ir a "Edición-Preferencias", elegir "Avanzadas", hacer clic en "Proxies", y en la ventana que aparece entonces, activar la opción de configurar manualmente los proxies.
Pinchar en "Ver" y en la ventana que aparece, poner en el campo de texto después de "HTTP:" los datos que correspondan según el esquema de abajo:
- Zona de Ciencias:
Aulas del edificio de Ciencias: web4.cti.unav.es
Aulas de la zona de Humanidades: web5.cti.unav.es
El correo electrónico es una de las herramientas más utilizadas desde los comienzos de Internet. Mediante correo electrónico es posible enviar cartas y mensajes a otras personas, a través de las redes de ordenadores. La generalización de su uso se debe a diversas ventajas en relación con las formas más tradicionales de correo:
El servidor de correo local recibe el mensaje y decide la mejor ruta para enviar el mensaje y lo transfiere a otro servidor de correo que esté en la ruta. Si no puede enviarlo lo almacena para retransmitirlo posteriormente.
El mensaje pasa de un servidor a otro hasta completar la ruta y llegar al ordenador en el que se haya el buzón del destinatario, desde donde éste lo leerá.
Independientemente del programa cliente que se utilice, para enviar un mensaje será necesario utilizar los siguientes parámetros:
-Dirección de correo electrónico del destinatario (To:): este dato es el más importante e imprescindible.
-Tema del mensaje (Subject): suele ser una palabra o una frase corta que da una idea del asunto a tratar.
-Copias a otros destinatarios(Cc): se pueden enviar copias del mensaje a otros destinatarios, además del principal. Para ello deben introducirse las direcciones de todos los destinatarios, en el campo de entrada Cc. El nombre de este campo viene de carbon copies "copias de carbón". La lista de los destinatarios aparecerá en todos los mensajes. Cada una de las personas que recibe una copia sabrá a qué otras personas se ha enviado el mensaje.
-Copias ocultas: algunos programas ofrecen la posibilidad de enviar copias a otros destinatarios, sin que su identificación figure en las copias de los demás. Los receptores del mensaje permanecerán ocultos. La lista de direcciones de los destinatarios ocultos debe introducirse en el campo Bcc. El nombre viene de Blind carbon copies.
Es conveniente seguir estas indicaciones:
Envíe mensajes cortos. Los usuarios se ven bombardeados con una infinidad de mensajes diariamente; en caso contrario, hará malgastar tiempo y dinero (más espacio en disco, tiempo de transmisión, etc.). Procure no contestar adjuntando todo el mail anterior.
Intente responder los mensajes de otras personas: se lo agradecerán. Esto no quiere decir que se responda a todos los mensajes que llegan a diario...
Afine con el título de sus mensajes, facilitará el trabajo de otros. Si tiene varios temas para tratar envíe varios mensajes.
Lea todo el mensaje antes de contestar. En muchas ocasiones se queda texto sin leer, lo que obliga a nuevas preguntas y re-envíos, y origina bastantes desconciertos y frustraciones.
Si puede, envíe un breve contexto (unas líneas) de lo tratado en el mail anterior. Por ejemplo, un mail con el texto "De acuerdo.", es bastante desconcertante.
Firme los mensajes. Puesto que algunos sistemas de mail quitan las cabeceras, su nombre puede no aparecer.
Recuerde que no siempre es posible expresar los estados de ánimo en un mail, y el conocimiento del estado de ánimo es una parte importante del contexto, y por tanto, de la interpretación. Una cosa manifestada con una sonrisa es totalmente diferente de su expresión escrita. Puede usar símbolos (smiley) para dar pistas:
:-) ;-) >-( 8-O
sonrisa guiño enfado asombro
En general, el humor y la ironía no funcionan bien con el e-mail. La ironía puede manifestarse con espacios _a d i c i o n a l e s_ o de otro modo, pero recuerde que las mayúsculas suelen emplearse para manifestar un enfado superlativo.
Evite distribuir mensajes a terceros sin el consentimiento explícito del autor: puede dejarle en muy mal lugar o provocar malos entendidos.
A este directorio se puede acceder desde la página web de la Universidad o directamente desde el correo electrónico que se esté usando en ese momento.
La dirección web del directorio electrónico de la Universidad es:
Para consultar el directorio electrónico directamente desde el programa de correo electrónico se deben configurar las preferencias del programa, dependiendo del programa la forma de configurarlo es muy distinta. Las instrucciones de configuración están en esta dirección:
http://www.unav.es/cti/email/conf/faq.html
Esta red, llamada Usenet, creció y se convirtió en un intercambio cooperativo y voluntario de noticias, evolucionando finalmente hacia grupos de discusión electrónicos. Mientras en algunos lugares es obligatorio pagar cierta cantidad por la recepción de las noticias, Usenet sigue reflejando sus orígenes como un proyecto académico diseñado para distribuir información de forma gratuita a todo aquel que lo desee.
Cada administrador de sistema decide qué grupos de noticias serán publicados en su sistema, de los 13.000 grupos que aproximadamente existen. Los grupos de noticias usan espacio de disco y ancho de banda muy valiosos, de tal manera que los administradores pueden decidir no usar ciertas jerarquías. Internet tiene muchos tipos de recursos, de los que Usenet es uno más. Usenet es usada también en redes que no forman parte de Internet.
Artículo es cada uno de los documentos existentes, relativos a un tema concreto. Dada la gran cantidad de artículos que cada día envían los usuarios y las limitaciones de espacio en los ordenadores, éstos duran poco tiempo en los servidores.
En un grupo de debate, cualquier participante puede comentar algún aspecto de la actualidad o realizar una consulta y, seguramente, habrá otros muchos dispuestos a responder, planteando a su vez opiniones alternativas o nuevas cuestiones.
Existen grupos de debate sobre la mayoría de las disciplinas:
técnicas, científicas, lúdicas, etc.
El servidor de News de la Universidad, suscrito a 600 grupos de discusión (hay varios miles), mantiene más de 100.000 artículos que se actualizan diariamente (unos 10.000 artículos/día), con una vida media de 10 días/artículo. Es posible suscribirse a nuevos grupos, para ello es suficiente pedirlo al CTI, mediante un mail a postmaster@news.cti.unav.es
La dirección del servidor de News es: news.cti.unav.es
Las listas de distribución son grupos de personas que se intercambian mensajes sobre una temática particular, compartiendo sus conocimientos y debatiendo temas de interés común, forman una comunidad virtual.
Sirven para canalizar información de interés, articular grupos de interés y para trabajos en grupo.
19.1. Diferencias entre Listas de Distribución y grupos de News
Deben de existir más de 5.000 grupos de noticias de diferentes de News de Usenet. Muchos de estos grupos de noticias son de interés local o regional y además los grandes sistemas no transportan mas de un par de miles de grupos de noticias. Puesto que las News proporcionan tal variedad de temas de discusión, es natural, preguntar qué diferencia hay entre grupos de noticias y Listas de distribución.
La primera gran diferencia es el escaso control que existe sobre las aportaciones a los grupos de News. Cualquier usuario puede enviar lo que desee a cualquier grupo de News. El resultado puede llegar a ser bastante desagradable. Es cierto que existen grupos de News moderados pero la propia filosofía del servicio, hace que la moderación sea un trabajo considerable. Las listas de distribución impiden enviar al foro si no se está suscrito.
19.1.1. Ventajas de las Listas de Distribución
2. Las Listas de Distribución aún siendo públicas siempre dispone de uno o varios administradores o moderadores que pueden tomar acciones ante eventos que desvirtúen el foro.
3. Los miembros de las Listas de Distribución siempre saben quién lee sus mensajes.
4. Los nuevos Servidores de Listas de Distribución optimizan la carga del buzón del usuario con opciones del estilo: INDEX, NOMAIL, DIGEST etc.
5.Los servidores implementan herramientas que detienen e impiden la distribución masiva de mensajes enviados a muchas listas. Supone que son mensajes con contenido "basura" y son eliminados.
6. Los servidores implementan algoritmos para optimizar el tráfico internacional.
7. Las Listas de Distribución son la herramienta mas adecuada para grupos de trabajo, discusiones importantes, debates o temas que se deban de leer con regularidad.
1. Gestión centralizada.
2. Origen histórico de las FAQs.
3. Los usuarios de las News son potencialmente todos los de Internet.
Hay dos conceptos importantes de distinguir:
1. Público: cualquier usuario tiene acceso a la información.
2. Privado: restringido a los miembros de la lista.
3. Administrador o Moderador: sólo la dirección de correo electrónico asociado al administrador o moderador.
4. Individual: sólo la dirección/es de correo electrónico asociada/s de forma específica.
5. Area: sólo un determinado subconjunto de direcciones de correo electrónico.
1. Darse de alta: Darse de alta en la lista.
2. Enviar mensajes: Aportar contribuciones a la lista.
3. Visualizar miembros: Posibilidad de visualizar los miembros suscritos a una lista.
4. Visualizar archivos: Posibilidad de ver los archivos de la lista.
La principal ventaja de una lista moderada es que sólo se reciben los mensajes más interesantes (en opinión del moderador). Muchas listas no moderadas tienen una gran cantidad de mensajes aburridos y redundantes que habrá que vadear para encontrar las verdaderas joyas. La moderación de una lista genera una gran cantidad de trabajo.
unsubscribe <list> [<address>]: da de baja a la dirección de origen o <address> de la lista <list>. "unsubscribe " le dará de baja de todas las listas en las que esté suscrito.
get <list> <filename>: trae el fichero <file> relacionado con la lista <list>.
index <list>: devuelve un índice de lo que podemos esperar de la lista <list>.
which [<address>]: nos dice en que listas esta suscrita la dirección de origen o <adress>.
who <list>: nos dice quien esta suscrito en la lista <list>.
info <list>: muestra la información introductoria de la lista <list>.
intro <list>: muestra el mensaje introductorio de la lista <list>, aunque sólo si estamos suscritos.
Lists: muestra las listas mantenidas por el servidor.
Help: muestra este mensaje de ayuda.
Estos comandos se deben enviar en el cuerpo o subject del mensaje de mail a listserv@unav.es. Siempre que vayan en líneas separadas se pueden ejecutar múltiples comandos.
Si se quiere conseguir información de las listas disponibles se envía un mail a listserv que diga:
Lists
Si se quiere suscribirse al grupo de pruebas se envía un mail a listser@unav.es que diga:
Subscribe unav-prueba
Si se quiere darse de baja, se envía un mail al mismo grupo que diga:
Unsubscribe unav-prueba.
Los programas y protocolos diseñados para llevar a cabo esta función se conocen con el nombre de FTP ( File Transfer Protocol).
En un principio, FTP era utilizado por profesionales que disponían para trabajar de varios ordenadores, para copiar de forma sencilla y rápida los programas y documentos que estaban almacenados en un ordenador a otro. En este caso era necesario que el usuario tuviese permiso de acceso a ambos ordenadores.
Posteriormente comenzó a utilizarse para compartir recursos de forma más global, creándose bibliotecas de ficheros, de acceso público a las que cualquier usuario podía acceder, a través de Internet, mediante un FTP anónimo. Actualmente existen millones de ficheros distribuidos en miles de ordenadores, que pueden ser copiados libremente y sin restricciones usando FTP anónimo. Estos ficheros pueden ser documentos, textos, imágenes, sonidos, programas, etc., contiendo todo tipo de datos e información.
Una de las aplicaciones más frecuentes de FTP anónimo es la obtención de software para todo tipo de ordenadores y sistemas operativos, por ejemplo, la mayoría de los programas utilizados en Internet pueden obtenerse de esta forma.
Telnet permite iniciar una sesión de trabajo en un ordenador remoto, o como suele decirse, realizar un login remoto.
A través de este procedimiento el teclado y el monitor del ordenador local se convierten en el terminal de un ordenador remoto que puede estar situado en cualquier parte del mundo.
Es posible ejecutar programas y utilizar los recursos e información disponibles en el anfitrión, aprovechando la capacidad de procesamiento y las herramientas que éste posea.
El WAIS (wide area information system) es un sistema de información pensado para acceder y buscar información en bases de datos distribuidas en ordenadores conectados a la red. Los servidores WAIS se basan en el protocolo z39.50 y permiten mantener bases de datos de texto completo, de imágenes, etc. El acceso a las bases de datos documentales WAIS se suele hacer desde servidores Gopher o WWW, que canalizan las consultas. Es más, el sistema de índices en los servidores Gopher y WWW se construye mediante un acceso o interface con un servidor WAIS.