¿Por qué comprimir?
En realidad solo hay una razón: Se comprime para ahorrar dinero. El ahorro puede estar en la capacidad de almacenamiento, en el ancho de banda de transmisión o en la cantidad de cinta necesaria.
¿Que es comprimir?
Fundamentalmente comprimir consiste en separar y eliminar la REDUNDANCIA que toda señal de video contiene y dejar solamente la INFORMACIÓN.
Se considera INFORMACIÓN todo aquello que el decodificador no puede obtener con los datos que le han llegado, le están llegando o le llegarán. Si lo puede obtener a partir de los datos pasados, presentes o futuros, entonces no es información, es redundancia.
Aunque existen varios tipos de Compresión, la utilizada en Televisión Digital es la que nos interesa. Se conoce como compresión PERCEPTUAL, llamada así porque la perdida de información sufrida durante el proceso de compresión-descompresión, no es detectada por el Sistema de Visión Humano.
Otro concepto que es preciso conocer para comprender los procesos de compresión, es el de ENTROPÍA, conocida en el ámbito de la física como la cantidad de desorden.
La ENTROPÍA, en el terreno de la compresión digital es la diferencia entre datos y redundancia, es decir la cantidad de información que contiene una imagen es su Entropía.
La Entropía se mide en (bpp) bits por pixel, es decir el número de bits necesarios para representar una imagen de manera inequívoca.
UN PAR DE EJEMPLOS:

Ya hemos visto que comprimir consiste en detectar y eliminar la REDUNDANCIA. Detectamos tres tipos de redundancia cuando analizamos una imagen de Televisión:
-REDUNDANCIA ESPACIAL: Cualquier pixel tiende a parecerse a los pixels vecinos.
-REDUNDANCIA TEMPORAL: Cualquier frame tiende a parecerse a los frames anterior y posterior en el tiempo.
-REDUNDANCIA ESTADÍSTICA: Determinados valores tienden a repetirse más que otros.
Para detectar la redundancia espacial, consideramos cada frame aisladamente.
Aunque se utilizan varios métodos para reducir el flujo binario teniendo en cuenta la
redundancia espacial, mostraré uno muy utilizado conocido como
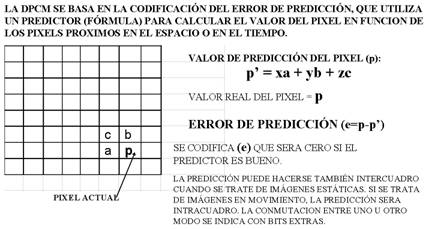
DPCM CON PREDICCIÓN ADAPTATIVA:
Este método consiste en calcular el valor de los pixels en función del valor de los adyacentes, mediante una fórmula denominada predictor, transmitiendo solamente el error de predicción, que evidentemente necesitará muchos menos bits que transmitir el valor absoluto de cada pixel.
Existe un método muy extendido de compresión intracuadro que elimina de manera muy eficaz la redundancia espacial. Se conoce como DCT (siglas en inglés de Transformada de Coseno Discreto). Básicamente consiste en dividir la imagen en cuadrados de 64 pixels (8 x 8) denominados bloques y realizar la transformada contemplando las 64 posibilidades que pueden ocurrir en cada bloque, desde la uniformidad total del bloque, es decir que todos los pixels tengan el mismo valor, hasta la posibilidad más compleja, en la que todos los pixels fueran alternativamente blancos y negros, pasando por todas las posibilidades intermedias, asignando unos coeficientes frecuenciales a cada una de las 64 posibilidades, desde la frecuencia espacial cero (DC), hasta la máxima frecuencia espacial horizontal y vertical.
La compresión o reducción del flujo binario se consigue transmitiendo solamente los coeficientes frecuenciales correspondientes a las bajas frecuencias y despreciando los correspondientes a las altas, ya que la entropía se polariza en las bajas frecuencias.
Este método tiene la ventaja de que se consiguen niveles importantes de compresión y además se puede elegir la relación de compresión a voluntad del usuario. Se utiliza por prácticamente todos los magnetoscopios digitales.
La compresión INTERFRAME, aquella que elimina la redundancia temporal, básicamente consiste en codificar solamente los pixels que cambian en un cuadro respecto a los anteriores.
Veamos un ejemplo:

F1 y F2 son dos frames sucesivos de una escena. Se codifica solamente la diferencia, es decir lo que ha cambiado F2 respecto a F1, utilizando muchos menos bits que si hubiera que codificar el frame completo.
Diferentes Tipos de Compresión
Compresión MPEG
Es un estándar definido específicamente para la compresión de
vídeo, utilizado para la transmisión de imágenes en vídeo digital. El
algoritmo que utiliza además de comprimir imágenes estáticas compara los
fotogramas presentes con los anteriores y los futuros para almacenar sólo las
partes que cambian. La señal incluye sonido en calidad digital. El
inconveniente de este sistema es que debido a su alta complejidad necesita
apoyarse en hardware específico.
Existen diferentes opciones dependiendo del uso:
MPEG-1 Estándar escogido por Vídeo-CD: calidad VHS con sonido digital.
MPEG-2 Se usa en los DVD (Digital Vídeo Disk). Calidad superior al MPEG-1.
MPEG-3 Gran calidad de vídeo: 1920x1080x30 Hz con transferencias entre 20 y 40
Mbps.
MPEG-4 Está en fase de desarrollo.
Compresión MJPEG(Moving Picture Expert Group)
Familia de normas de compresión elaborada por diferentes grupos de expertos representativos de la Industria Televisiva de todo el mundo.
Básicamente consiste en tratar al vídeo como una secuencia de imágenes estáticas independientes y su compresión y descompresión mediante el algoritmo JPEG, para luego, recomponer la imagen de vídeo. Esto se puede realizar en tiempo real e incluso con poca inversión en hardware. El inconveniente de este sistema es que no se puede considerar como un estándar de vídeo pues ni siquiera incluye la señal de audio. Oro problema es que la dependencia que tiende de las transferencias del sistema de almacenamiento, pues el índice de compresión no es muy grande. En la práctica es factible conseguir la calidad SVHS con lo que se pueden realizar trabajos semiprofesionales.
En lo que respecta a la TV Digital, interesa la familia MPEG2 que se estructura en diferentes niveles y perfiles.
En el protocolo MPEG, se establecen tres tipos de imágenes:
IMAGENES "I": Codificación intracuadro.Se elimina la redundancia espacial y estadística.
IMAGENES "P": Predicción unidireccional en el tiempo obtenida a partir de imágenes "I" o "P".
IMAGENES "B": Predicción Bidireccional a partir de imágenes "I" o "P".
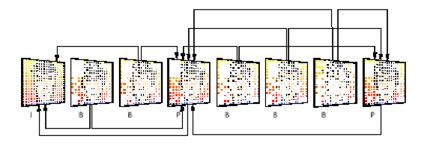
Se define el término GOP (Group of Pictures) como el número de cuadros entre dos imágenes I.
Las imágenes I inician la secuencia GOP y son las que más información contiene, y por tanto las que más bits ocupan.
Las imágenes P y B tienen un fuerte grado de compresión.
El proceso de compresión en MPEG funciona de acuerdo con la siguiente secuencia:
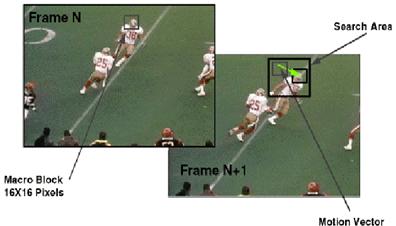
1.- Se divide cada imágen en cuadrados de 16x16 pixels llamados Macrobloques.
2.- Se codifican con técnicas intracuadro las imágenes I.
3.- Se comparan los Macrobloques correlativos del Cuadro I con respecto al P.
4.- Los Macrobloques que coincidan, no se codifican.
5.- El Macrobloque que no coincida se busca en los alrededores.
6.- Si se encuentra y es idéntico, se codifican solamente los vectores de desplazamiento.
7.- Si no se encuentra idéntico, se codifica la diferencia con el mas parecido, mas los vectores de desplazamiento.
La estructura del flujo de datos de una señal de video codificada en MPEG, viene definida por los siguientes elementos secuenciados de mayor a menor: Secuencias, GOP´s, Imágenes, Slides, Macrobloques y Bloques.
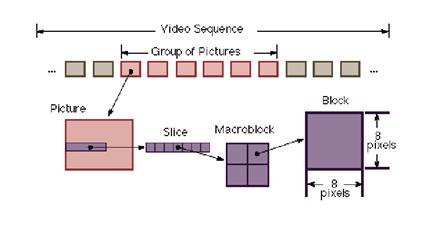
Cada uno de estos elementos va precedido de una cabecera de datos que especifican los atributos del mismo, de tal manera que faciliten el trabajo del decodificador:
SECUENCIA: Consta de varios GOP´s, indicando los datos de la cabecera la relación de aspecto, el Flujo Binario y otros relacionados con un mismo contenido de programa.
GOP:(Group of Pictures): Grupo de imágenes, normalmente 12 frames. Constituye la unidad de compresión temporal.
IMAGEN: Puede ser I, P o B, indicandose este dato en los bits de cabecera.
SLICE: Consta de varios macrobloques asociados en sentido horizontal. Puede comprender desde un solo macrobloque hasta toda la línea. Si en los procesos de transmisión se produce un error irreparable, se pierde el slice completo.
MACROBLOQUE: Asociación de 4 Bloques. Consta de 256 pixels (16x16). Es la unidad de comparación para el cálculo de los vectores de desplazamiento. La cabecera indicará el método de codificación.
BLOQUE: Cuadrado de 64 pixels (8x8). Unidad de procesado DCT.
La familia MPEG se divide en Perfiles y Niveles. Los Perfiles definen la resolución de color y la escalabilidad de la corriente de datos. Los Niveles definen los máximos y mínimos de resolución de imágen, las muestras por segundo de la Luminancia y el máximo flujo binario para cada perfil.
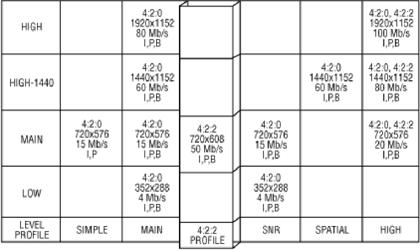
La combinación de perfiles y niveles produce una arquitectura que define la capacidad de un codificador para manejar un determinado flujo binario.
La combinación del nivel principal perfil principal es la utilizada en distribución y emisión de Televisión Digital Profesional. Una variante de esta combinación, denominada 4:2:2, se pretende utilizar para captura, post-producción y emisión.